
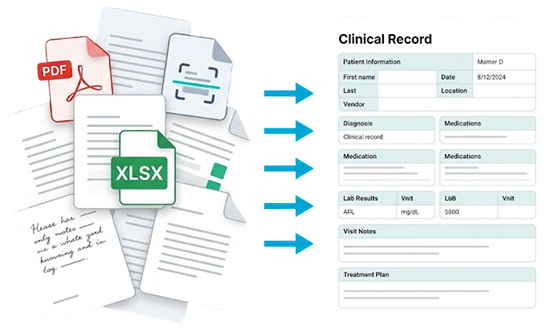

PDF Medical Records
Structured or unstructured both work.

Scanned and Image-Based Documents
OCR built in. No separate tool needed.

Bulk Uploads via CSV or XLSX
No Reformatting Required

SOAP Notes and Clinical Memos
Typed notes go straight in.
PDF Medical Records
Structured or unstructured both work.
Scanned and Image-Based Documents
OCR built in. No separate tool needed.
SOAP Notes and Clinical Memos
Typed notes go straight in.
Bulk Uploads via CSV or XLSX
No Reformatting Required

Submit document in any supported format

OCR and extraction runs automatically

Clinical content is parsed and structured
